Automatically assessing handwritten mathematical solutions is an important problem in educational technology with practical applications, but it remains a significant challenge due to the diverse formats, unstructured layouts, and symbolic complexity of student work. To address this challenge, we introduce VEHME-a Vision-Language Model for Evaluating Handwritten Mathematics Expressions—designed to assess open-form handwritten math responses with high accuracy and interpretable reasoning traces. VEHME integrates a two-phase training pipeline: (i) supervised fine-tuning using structured reasoning data, and (ii) reinforcement learning that aligns model outputs with multi-dimensional grading objectives, including correctness, reasoning depth, and error localization. To enhance spatial understanding, we propose an Expression-Aware Visual Prompting Module, trained on our synthesized multi-line math expressions dataset to robustly guide attention in visually heterogeneous inputs. Evaluated on AIHub and FERMAT datasets, VEHME achieves state-of-the-art performance among open-source models and approaches the accuracy of proprietary systems, demonstrating its potential as a scalable and accessible tool for automated math assessment. Our training and experiment code is publicly available at our GitHub repository.
Our approach to Handwritten Mathematics Grading integrates two key components: (1) supervised fine-tuning using distilled data from the QwQ-32B model to instill foundational reasoning capabilities, and (2) reinforcement learning via Group Relative Policy Optimization to refine the model's ability to generate accurate and explainable grading outputs. As shown in the Figure, this dual-phase training strategy aims to enhance both the correctness assessment and the interpretability of the model's evaluations.
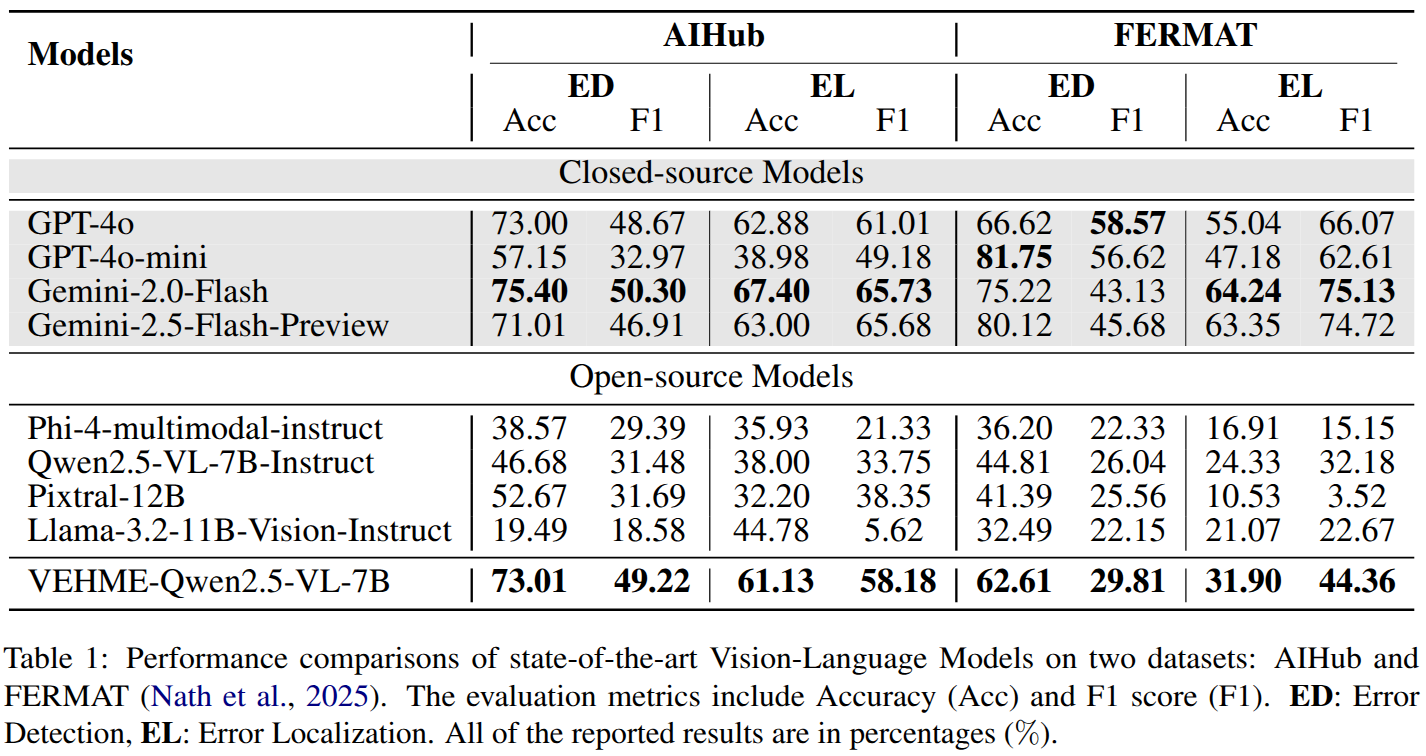
The experiments are conducted on two tasks--Error Detection and Error Localization, across the AIHub and FERMAT datasets.
The Table above compares our VEHME-Qwen2.5-VL-7B against four open-source baselines and four closed-source systems on the AIHub and FERMAT benchmarks.
Among the open-source group, our model achieves a clear lead in both Error Detection (ED) and Error Localization (EL).
On AIHub, VEHME records 73.01% ED accuracy (49.22% F1) and 61.13% EL accuracy (58.18% F1), substantially outperforming Qwen2.5-VL-7B-Instruct (46.68%Acc/ 31.48% F1 for ED, 38.00% Acc/ 33.75% F1 for EL), Pixtral-12B (52.67% / 31.69% ED, 32.20% / 38.35% EL), Phi-4-multimodal-instruct, and Llama-3.2-11B.
This margin highlights the effectiveness of our data synthesis pipeline and dual-phase training in refining both expression recognition and precise localization.
On FERMAT, open-source models generally struggle, but our approach again leads the pack with 62.61% ED accuracy (29.81% F1) and 31.90% EL accuracy (44.36% F1).
Notably, Pixtral-12B exhibits an unusual split—high ED accuracy (41.39%) yet very low EL performance (10.53% Acc/3.52% F1)--which echoes the observations in the original FERMAT study: its format alignment and output consistency are suboptimal for localization tasks.
In contrast, our model's balanced gains across both metrics demonstrate robust adherence to the expected answer format and reliable spatial grounding.
When we turn to closed-source systems, Gemini-2.0-Flash remains the top performer overall (75.40%/50.30% ED, 67.40%/65.73% EL on AIHub; 75.22%/43.13% ED, 64.24%/75.13% EL on FERMAT), followed closely by GPT-4o and its mini variant.
These proprietary models, however, exceed tens or even hundreds of billions of parameters, whereas our Qwen2.5-VL-7B backbone contains only 7 billion parameters.
The result demonstrates that our lightweight model surpasses other open-source approaches and nearly matches closed-source models, while operating at a fraction of the scale of closed systems, underscoring the efficiency gains enabled by our targeted data generation and training regimen.
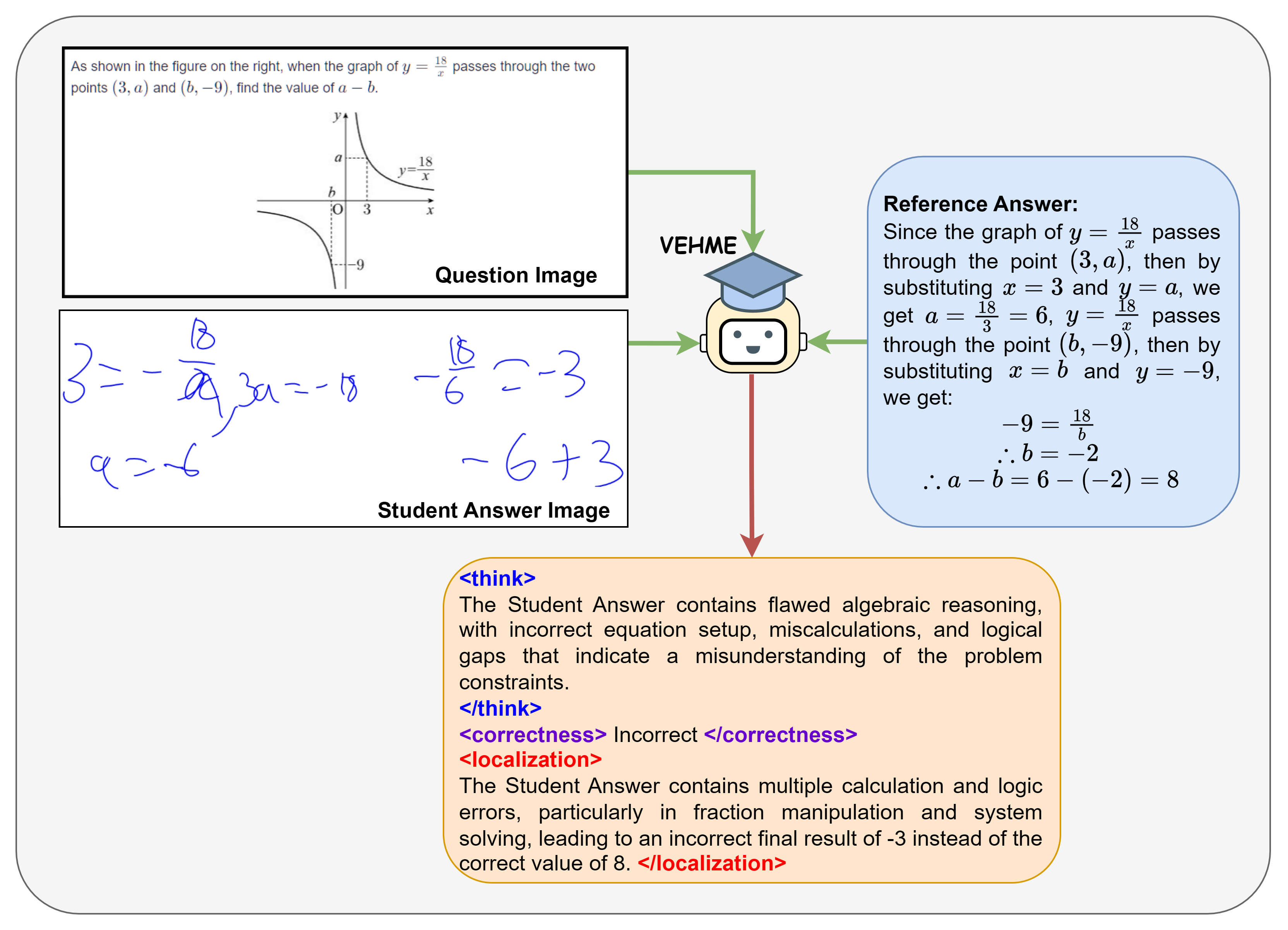
The following Figures illustrate qualitative examples of VEHME's grading outputs on AIHub samples.
 Qualitative example for Error Detection (ED). Among the 7 models, VEHME provides the most correct
error detection. The model's error is colored in red. The incorrect response from the models can be categorized
into 3 main types: “recognition error”, “problem misunderstanding”, and “hallucination”. Pixtral, GPT, Qwen2.5,
and Gemini all suffer from incorrect OCR of the student's handwritten mathematical expressions. While Pixtral
still produces the correct assessment, its thought was wrong due to incorrect OCR. Phi-4 misinterprets the problem
as solving the inequality, while the problem is asking to find the maximum value of a. Llama3.2 suffers from
hallucination where its thought is correct, but the final assessment is incorrect.
Qualitative example for Error Detection (ED). Among the 7 models, VEHME provides the most correct
error detection. The model's error is colored in red. The incorrect response from the models can be categorized
into 3 main types: “recognition error”, “problem misunderstanding”, and “hallucination”. Pixtral, GPT, Qwen2.5,
and Gemini all suffer from incorrect OCR of the student's handwritten mathematical expressions. While Pixtral
still produces the correct assessment, its thought was wrong due to incorrect OCR. Phi-4 misinterprets the problem
as solving the inequality, while the problem is asking to find the maximum value of a. Llama3.2 suffers from
hallucination where its thought is correct, but the final assessment is incorrect.
 Qualitative example for Error Localization (EL). Among the 7 models, VEHME provides the most
correct localization. The model's error is colored in red. The incorrect response from the models can be categorized
into 2 main types: “recognition error” and “student's answer misunderstanding”. Pixtral, Phi-4, and Gemini all
suffer from incorrect OCR of the student's handwritten mathematical expressions. Pixtral and Gemini misread
the inequality 4x ≤ 120 while Phi-4 cannot read beyond the inequality 2x + 5. GPT, Qwen2.5, and Llama3.2
misinterpret the student's answer. GPT and Qwen2.5 think that the student writes 2x + 5 as the perimeter, while
Llama3.2 thinks that the student must determine the number of sides.
Qualitative example for Error Localization (EL). Among the 7 models, VEHME provides the most
correct localization. The model's error is colored in red. The incorrect response from the models can be categorized
into 2 main types: “recognition error” and “student's answer misunderstanding”. Pixtral, Phi-4, and Gemini all
suffer from incorrect OCR of the student's handwritten mathematical expressions. Pixtral and Gemini misread
the inequality 4x ≤ 120 while Phi-4 cannot read beyond the inequality 2x + 5. GPT, Qwen2.5, and Llama3.2
misinterpret the student's answer. GPT and Qwen2.5 think that the student writes 2x + 5 as the perimeter, while
Llama3.2 thinks that the student must determine the number of sides.
Check out our code for more details on how to use VEHME: Tutorial
@inproceedings{nguyen-etal-2025-vehme,
title = "{VEHME}: A Vision-Language Model For Evaluating Handwritten Mathematics Expressions",
author = "Nguyen, Thu Phuong and
Nguyen, Duc M. and
Jeon, Hyotaek and
Lee, Hyunwook and
Song, Hyunmin and
Ko, Sungahn and
Kim, Taehwan",
editor = "Christodoulopoulos, Christos and
Chakraborty, Tanmoy and
Rose, Carolyn and
Peng, Violet",
booktitle = "Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.emnlp-main.1619/",
pages = "31781--31801",
ISBN = "979-8-89176-332-6",
abstract = "Automatically assessing handwritten mathematical solutions is an important problem in educational technology with practical applications, but remains a significant challenge due to the diverse formats, unstructured layouts, and symbolic complexity of student work. To address this challenge, we introduce VEHME-a $\textbf{V}$ision-Language Model for $\textbf{E}$valuating $\textbf{H}$andwritten $\textbf{M}$athematics $\textbf{E}$xpressions{---}designed to assess open-form handwritten math responses with high accuracy and interpretable reasoning traces. VEHME integrates a two-phase training pipeline: (i) supervised fine-tuning using structured reasoning data, and (ii) reinforcement learning that aligns model outputs with multi-dimensional grading objectives, including correctness, reasoning depth, and error localization. To enhance spatial understanding, we propose an Expression-Aware Visual Prompting Module, trained on our synthesized multi-line math expressions dataset to robustly guide attention in visually heterogeneous inputs. Evaluated on AIHub and FERMAT datasets, VEHME achieves state-of-the-art performance among open-source models and approaches the accuracy of proprietary systems, demonstrating its potential as a scalable and accessible tool for automated math assessment. Our training and experiment code is publicly available at our GitHub repository."
}